![]()
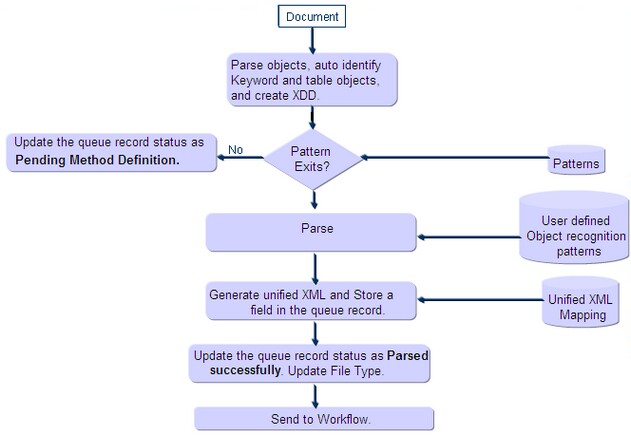
![]() After a file is uploaded into the system, the system may "recognize" the file using a recognition (routing) pattern (FRP) that matches the file. In this case, a file type and a data recognition (extraction) pattern (DRP) can be automatically assigned to the file and the document is then parsed. In some cases, the document is attached to a workflow. If the system does not recognize the file pattern, the queue record is assigned a pending pattern definition which requires the user to update or create FRP and DRP templates for the document. These templates are created using the Document Template Designer window.
After a file is uploaded into the system, the system may "recognize" the file using a recognition (routing) pattern (FRP) that matches the file. In this case, a file type and a data recognition (extraction) pattern (DRP) can be automatically assigned to the file and the document is then parsed. In some cases, the document is attached to a workflow. If the system does not recognize the file pattern, the queue record is assigned a pending pattern definition which requires the user to update or create FRP and DRP templates for the document. These templates are created using the Document Template Designer window.
The Document Template Designer window allows you to conduct two types of extractions - statistical and content based. FRPs are used to recognize file types by identifying meta-tags in the document that are typically related to certain file types. For example, a document that contains the meta-tags: Equipment ID, Test Results, Sample Information, and so on, can be recognized as an instrument output file. Thus, during the recognition process, the system will attempt automatically to move the document to the matching file-type. After the FRP is created, a DRP can be created to contain the data extraction method, that is, the DRP is used to convert unstructured information in the file to structured data in the form of XML. After the templates are created, information extracted from the document can be bound to a Unified XML structure which can be read by external applications, such as a LIMS.
![]() NOTE In order to create templates for a document, you must have the appropriate permissions; otherwise, you can only view the Unified XML generated from the document.
NOTE In order to create templates for a document, you must have the appropriate permissions; otherwise, you can only view the Unified XML generated from the document.
The following diagram displays how documents are processed: